Because of the recent SoftLayer acquisition, SmartCloud Enterprise (SCE) was sunset January 31st 2014. There were just to many overlaps between the two offerings and SoftLayer seemed to me the more mature platform with more functionality. So, that SCE was stopped (and functionality like SCAS is merged into SoftLayer) was not much of a surprise.
But what does this mean for SCE+ – or, what should it mean for it?
First of all, it means a name change. As announced on this year’s Pulse (IBM’s cloud conference), SCE+ will be rebranded to Cloud Managed Services (CMS).
Second, the good news, CMS/SCE+ will stay with a strong roadmap at least until 2017 (well, the roadmap is specified until 2017, so it is very likely that CMS/SCE+ will stay even beyond 2017. But who knows what happens in IT in the next 5 years 🙂
But why two offerings anyway?
In an essence, SCE+ and SoftLayer are positioned the same way as SCE+ and SCE were originally positioned:
- SCE+ for cloud enabled workloads
- SoftLayer for cloud native workloads
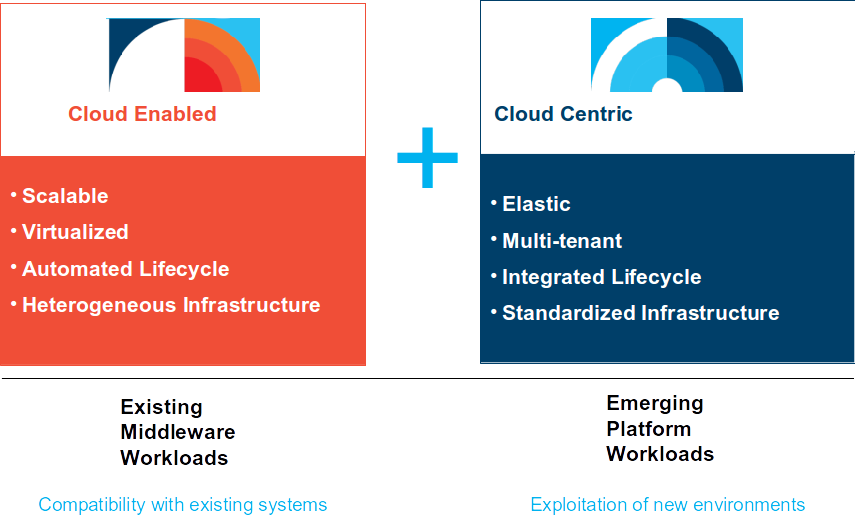
To understand this positioning a little bit better, lets discuss the current capabilities of each offering and the current planned roadmap items:
SoftLayer
SoftLayer provides a highly flexible IaaS platform for cloud centric workloads. The underlying infrastructure is highly standardized and gives full control to the client for everything above the hypervisor including the operating system. Even if the client subscribes to one of the offered management options, it mainly means, SoftLayer is providing limited management tasks on a best can do basis, but without real SLAs and the client maintains full admin access to its instances.
The platform provides high flexibility, so all kind of possible setups can be implemented (by clients), but the responsibility for a given setup remains at the client, not at SoftLayer. In a nutshell, SoftLayer provides an IaaS environment with a very high degree of freedom and control for clients without taking over responsibilities for anything above the hypervisor.
These capabilities fit well for cloud centric or self-managed development (DevOps) workloads, but less for traditional high available workloads like SAP.
Cloud Managed Services (formally known as SmartCloud Enterprise+)
CMS on the other hand was designed and built to meet exactly the requirements of high available, managed production workloads originally hosted in client’s datacenters. CMS provides SLAs and technologies for accomodating high available workloads like clustering and disaster recovery (R1.4). While D/R setups can also be created on SoftLayer, the client must design, build and run them, but can not receive them as a service. This is the main differentiator in the SoftLayer / CMSpositioning. CMS is less flexible above the hypervisor, as it provides managed high available operating systems as a Service with given SLAs. To meet these SLAs, standards must be met and the underlying infrastructure must be technically capable to provide these SLAs (Tier 1 storage).
Due to the guaranteed service levels on the OS layer, this is IBM’s preferred platform for PaaS offerings of rather traditional software stacks like SAP or Oracle applications.
Summary
There are a lot of usecases were SoftLayer does not fit and CMS is the answer to fulfull the requirements. Based on the very clear distinct workloads for SoftLayer and CMS, there are no reasons to think about a CMS retirement.
